Tutorial spatial
This tutorial is for running NS-Forest for spatial transcriptomic gene panel design.
The first step is filtering non-zero median expression of all genes represented in the AnnData object. This is done by taking the expression values for each gene for all cells, removing the zero values, and calculating the median per gene. Median is used instead of mean because mean is sensitive to outliers and skewed with noise. We can visualize these genes’ non-zero median expression in a histogram and plot the 10th and 99th percentiles. We remove genes with relatively low or high expression. High expression can effect the spatial imaging results due to “optical crowding”, resulting from excessive fluorescent signal from high transcript dense regions (https://www.nature.com/articles/s41467-021-27798-0).
The next step is filtering by transcript length. In spatial transcriptomics, probes are designed to target each gene; genes with more probes tend to have higher sensitivity to be detected (https://pmc.ncbi.nlm.nih.gov/articles/PMC10054990/). The minimum transcript length is to ensure high detection. The transcript lengths are from Gencode’s BioMart. Due to multiple transcript lengths associated with a single gene, the longest length is choosen. The NS-Forest package contains the gencode
files for human (v47) and mouse (vM36), which can be found in the gencode_annotation folder. The default minimum transcript length is 700. This value is adjustable depending on the organ and species. For example, when looking at a mouse brain dataset, we chose 700 to include Sst (721bp), which is a well known neuronal inhibitory marker gene.
Note: adata.var.index should be unique. It is recommended that the adata.var_names be the ensembl_id, but gene_symbol should work.
After running spaceTx_genefilter, the standard NS-Forest pipeline is run, including prep_medians, prep_binary_score, and nsforesting.NSForest. This pipeline outputs a set of 1-6 markers per cell type that can be used for spatial transcriptomic gene panel.
Setting up environment
[1]:
import sys
import os
code_folder = "C:/Users/bpeng/OneDrive - J. Craig Venter Institute/Documents/Github/NSForest"
sys.path.insert(0, os.path.abspath(code_folder))
import numpy as np
import pandas as pd
import scanpy as sc
import anndata as ad
import matplotlib.pyplot as plt
import plotly.io as pio
pio.renderers.default = "notebook"
import nsforest as ns
from nsforest import utils
[2]:
cluster_header = "cluster"
output_folder = "../outputs_layer1_spatial/"
data_folder = "../demo_data/"
file = data_folder + "adata_layer1.h5ad"
adata = sc.read_h5ad(file)
adata
[2]:
AnnData object with n_obs × n_vars = 871 × 16497
obs: 'cluster'
Filtering genes to optimize spatial gene panels.
[3]:
adata = ns.pp.spaceTx_genefilter(adata, gencode_folder = f"{code_folder}/gencode_annotation")
adata
Non-zero median expression percentile limits:
0.10 1.584962
0.99 8.898539
dtype: float64
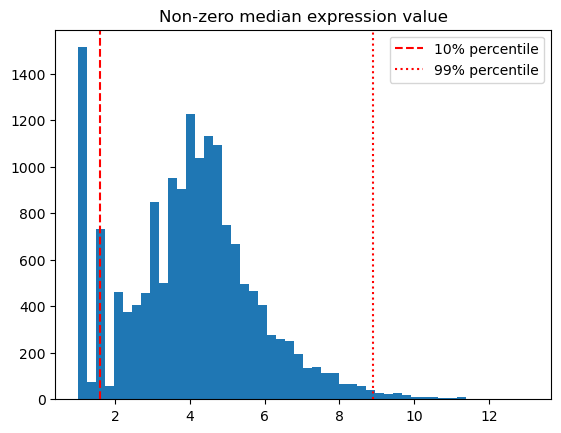
FILTER 1: 13944 out of 16497 total genes passed the expression filter (lower_percentile = 0.1, upper_percentile = 0.99).
FILTER 2: 14278 out of 16497 total genes passed the transcript length filter (min_txLength = 700).
FINAL SELECTION: 12147 out of 16497 total genes passed both filters.
[3]:
AnnData object with n_obs × n_vars = 871 × 12147
obs: 'cluster'
Calculating medians and binary scores per cluster
[4]:
adata = ns.pp.prep_medians(adata, cluster_header)
adata = ns.pp.prep_binary_scores(adata, cluster_header)
Calculating medians per cluster: 100%|██████████| 16/16 [00:01<00:00, 10.98it/s]
Saving medians as adata.varm.medians_cluster
median: 0.0
mean: 1.828
std: 2.518
Only positive genes selected. 9402 positive genes out of 12147 total genes
--- 1.6438896656036377 seconds ---
Calculating binary scores per cluster: 100%|██████████| 16/16 [01:11<00:00, 4.46s/it]
Saving binary scores as adata.varm.binary_scores_cluster
median: 0.118
mean: 0.207
std: 0.251
--- 71.59167551994324 seconds ---
Running NS-Forest
[5]:
outputfilename_prefix = cluster_header
results = ns.nsforesting.NSForest(adata, cluster_header, save_supplementary = True, save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Running NS-Forest version 4.1
Preparing adata...
Pre-selecting genes based on binary scores...
BinaryFirst_high Threshold (mean + 2 * std): 0.709
Average number of genes after gene_selection in each cluster: 577.5625
Saving number of genes selected per cluster as...
../outputs_layer1_spatial/cluster_gene_selection.csv
--- 0.04798698425292969 seconds ---
Number of clusters to evaluate: 16
1 out of 16:
e1_e299_SLC17A7_L5b_Cdh13
Pre-selected 1122 genes to feed into Random Forest.
NSForest-selected markers: ['SLC17A7', 'ANKRD33B']
fbeta: 0.959
precision: 0.988
recall: 0.856
2 out of 16:
g1_g48_GLI3_Astro_Gja1
Pre-selected 441 genes to feed into Random Forest.
NSForest-selected markers: ['LINC00498']
fbeta: 0.95
precision: 1.0
recall: 0.792
3 out of 16:
g2_g27_APBB1IP_Micro_Ctss
Pre-selected 281 genes to feed into Random Forest.
NSForest-selected markers: ['C1QC']
fbeta: 0.935
precision: 1.0
recall: 0.741
4 out of 16:
g3_g18_GPNMB_OPC_Pdgfra
Pre-selected 251 genes to feed into Random Forest.
NSForest-selected markers: ['COL20A1']
fbeta: 0.833
precision: 1.0
recall: 0.5
5 out of 16:
g4_g9_MOG_Oligo_Opalin
Pre-selected 401 genes to feed into Random Forest.
NSForest-selected markers: ['CNDP1']
fbeta: 0.976
precision: 1.0
recall: 0.889
6 out of 16:
i10_i16_TSPAN12_Vip_Mybpc1
Pre-selected 811 genes to feed into Random Forest.
NSForest-selected markers: ['CHRNB3', 'WIF1']
fbeta: 0.865
precision: 1.0
recall: 0.562
7 out of 16:
i11_i6_EGF_Vip_Mybpc1
Pre-selected 1459 genes to feed into Random Forest.
NSForest-selected markers: ['FZD8']
fbeta: 0.556
precision: 0.667
recall: 0.333
8 out of 16:
i1_i90_COL5A2_Ndnf_Car4
Pre-selected 191 genes to feed into Random Forest.
NSForest-selected markers: ['COL5A2', 'TRPC3']
fbeta: 0.845
precision: 1.0
recall: 0.522
9 out of 16:
i2_i77_LHX6_Sst_Cbln4
Pre-selected 212 genes to feed into Random Forest.
NSForest-selected markers: ['LHX6', 'GRIK3']
fbeta: 0.857
precision: 1.0
recall: 0.545
10 out of 16:
i3_i56_BAGE2_Ndnf_Cxcl14
Pre-selected 110 genes to feed into Random Forest.
NSForest-selected markers: ['SCN5A', 'GREM2']
fbeta: 0.642
precision: 0.826
recall: 0.339
11 out of 16:
i4_i54_MC4R_Ndnf_Cxcl14
Pre-selected 163 genes to feed into Random Forest.
NSForest-selected markers: ['ADAM33', 'NDNF', 'CD36']
fbeta: 0.783
precision: 0.929
recall: 0.481
12 out of 16:
i5_i47_TRPC3_Ndnf_Car4
Pre-selected 773 genes to feed into Random Forest.
NSForest-selected markers: ['TRPC3', 'CA2']
fbeta: 0.828
precision: 0.962
recall: 0.532
13 out of 16:
i6_i44_GPR149_Vip_Mybpc1
Pre-selected 303 genes to feed into Random Forest.
NSForest-selected markers: ['GPR149', 'SHISA8', 'ASIC4']
fbeta: 0.757
precision: 0.852
recall: 0.523
14 out of 16:
i7_i31_CLMP_Ndnf_Cxcl14
Pre-selected 829 genes to feed into Random Forest.
NSForest-selected markers: ['RASSF3', 'PAX6', 'CPLX3']
fbeta: 0.841
precision: 0.947
recall: 0.581
15 out of 16:
i8_i27_SNCG_Vip_Mybpc1
Pre-selected 1082 genes to feed into Random Forest.
NSForest-selected markers: ['SNCG', 'EDNRA']
fbeta: 0.759
precision: 0.923
recall: 0.444
16 out of 16:
i9_i22_TAC3_Vip_Mybpc1
Pre-selected 812 genes to feed into Random Forest.
NSForest-selected markers: ['MCTP2', 'ANGPT1']
fbeta: 0.806
precision: 1.0
recall: 0.455
--- 80.83747506141663 seconds ---
Saving supplementary table as...
../outputs_layer1_spatial/cluster_supplementary.csv
Saving markers table as...
../outputs_layer1_spatial/cluster_markers.csv
using median
Calculating medians per cluster: 100%|██████████| 16/16 [00:00<00:00, 379.53it/s]
Saving supplementary table as...
../outputs_layer1_spatial/cluster_markers_onTarget_supp.csv
Saving supplementary table as...
../outputs_layer1_spatial/cluster_markers_onTarget.csv
Saving final results table as...
../outputs_layer1_spatial/cluster_results.csv
Saving final results table as...
../outputs_layer1_spatial/cluster_results.pkl
[6]:
results
[6]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | NSForest_markers | binary_genes | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.958801 | 0.988417 | 0.856187 | 569 | 3 | 43 | 256 | 2 | [SLC17A7, ANKRD33B] | [SLC17A7, ANKRD33B, SFTA1P, TBR1, LINC00152, N... | 1.000000 |
| 1 | 4.1 | cluster | g1_g48_GLI3_Astro_Gja1 | 48 | 0.950000 | 1.000000 | 0.791667 | 823 | 0 | 10 | 38 | 1 | [LINC00498] | [LINC00498, SLC25A18, FGFR3, EMX2OS, ALDH1L1, ... | 1.000000 |
| 2 | 4.1 | cluster | g2_g27_APBB1IP_Micro_Ctss | 27 | 0.934579 | 1.000000 | 0.740741 | 844 | 0 | 7 | 20 | 1 | [C1QC] | [CSF2RA, C1QC, SYK, P2RY13, FGD2, MS4A7, CX3CR... | 1.000000 |
| 3 | 4.1 | cluster | g3_g18_GPNMB_OPC_Pdgfra | 18 | 0.833333 | 1.000000 | 0.500000 | 853 | 0 | 9 | 9 | 1 | [COL20A1] | [OLIG2, STK32A, COL20A1, KLRC3, B3GNT7, CSPG4,... | 1.000000 |
| 4 | 4.1 | cluster | g4_g9_MOG_Oligo_Opalin | 9 | 0.975610 | 1.000000 | 0.888889 | 862 | 0 | 1 | 8 | 1 | [CNDP1] | [MOBP, CNDP1, TF, ASPA, CLMN, CD22, PPP1R14A, ... | 1.000000 |
| 5 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.865385 | 1.000000 | 0.562500 | 855 | 0 | 7 | 9 | 2 | [CHRNB3, WIF1] | [TSPAN12, TMC5, CHRNB3, ANGPT1, DCN, WIF1, HCR... | 0.494252 |
| 6 | 4.1 | cluster | i11_i6_EGF_Vip_Mybpc1 | 6 | 0.555556 | 0.666667 | 0.333333 | 864 | 1 | 4 | 2 | 1 | [FZD8] | [EGF, XYLT2, FZD8, ZSCAN23, NSRP1P1, RPUSD4, S... | 1.000000 |
| 7 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.845324 | 1.000000 | 0.522222 | 781 | 0 | 43 | 47 | 2 | [COL5A2, TRPC3] | [NMBR, BMP2, COL5A2, ADRA1D, TRPC3, PAPSS2, BM... | 0.618906 |
| 8 | 4.1 | cluster | i2_i77_LHX6_Sst_Cbln4 | 77 | 0.857143 | 1.000000 | 0.545455 | 794 | 0 | 35 | 42 | 2 | [LHX6, GRIK3] | [LHX6, RSPO3, CALB1, TAC1, TRBC2, GRIK3, MAFB,... | 0.942058 |
| 9 | 4.1 | cluster | i3_i56_BAGE2_Ndnf_Cxcl14 | 56 | 0.641892 | 0.826087 | 0.339286 | 811 | 4 | 37 | 19 | 2 | [SCN5A, GREM2] | [SCN5A, GREM2, SYT10, ARHGAP18, ZNF423, GRB14,... | 0.531211 |
| 10 | 4.1 | cluster | i4_i54_MC4R_Ndnf_Cxcl14 | 54 | 0.783133 | 0.928571 | 0.481481 | 815 | 2 | 28 | 26 | 3 | [ADAM33, NDNF, CD36] | [EGFL6, ADAM33, PGAM1P5, CHRNB3, NDNF, CD36, A... | 0.351766 |
| 11 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.827815 | 0.961538 | 0.531915 | 823 | 1 | 22 | 25 | 2 | [TRPC3, CA2] | [SOX13, PRSS12, SSTR2, TRPC3, PAPSS2, CA2, HAP... | 0.448483 |
| 12 | 4.1 | cluster | i6_i44_GPR149_Vip_Mybpc1 | 44 | 0.756579 | 0.851852 | 0.522727 | 823 | 4 | 21 | 23 | 3 | [GPR149, SHISA8, ASIC4] | [CXCL12, GPR149, SHISA8, IGFBP5, PXDN, ASIC4, ... | 0.546603 |
| 13 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.841121 | 0.947368 | 0.580645 | 839 | 1 | 13 | 18 | 3 | [RASSF3, PAX6, CPLX3] | [FGF10, RASSF3, CLMP, PAX6, SP8, CPLX3, TGFBR2... | 0.629389 |
| 14 | 4.1 | cluster | i8_i27_SNCG_Vip_Mybpc1 | 27 | 0.759494 | 0.923077 | 0.444444 | 843 | 1 | 15 | 12 | 2 | [SNCG, EDNRA] | [SNCG, EDNRA, MMRN2, FBN3, RGS2, SCML4, NRP2, ... | 1.000000 |
| 15 | 4.1 | cluster | i9_i22_TAC3_Vip_Mybpc1 | 22 | 0.806452 | 1.000000 | 0.454545 | 849 | 0 | 12 | 10 | 2 | [MCTP2, ANGPT1] | [BSPRY, OFD1P10Y, MCTP2, ARHGAP29, FHDC1, ANGP... | 0.752842 |