Tutorial evaluating
This tutorial is for running NS-Forest’s evaluation module for evaluating marker sets’ classification.
Setting up environment
[1]:
import sys
import os
code_folder = "C:/Users/bpeng/OneDrive - J. Craig Venter Institute/Documents/Github/NSForest"
sys.path.insert(0, os.path.abspath(code_folder))
import numpy as np
import pandas as pd
import scanpy as sc
import anndata as ad
import matplotlib.pyplot as plt
import plotly.io as pio
pio.renderers.default = "notebook"
import nsforest as ns
from nsforest import utils
Data Exploration
Loading h5ad AnnData file
[2]:
cluster_header = "cluster"
output_folder = "../outputs_layer1/"
data_folder = "../demo_data/"
file = data_folder + "adata_layer1.h5ad"
adata = sc.read_h5ad(file)
adata
[2]:
AnnData object with n_obs × n_vars = 871 × 16497
obs: 'cluster'
[3]:
ns.pp.dendrogram(adata, cluster_header)
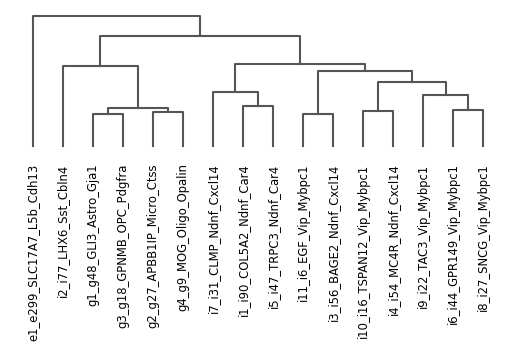
Evaluating input marker list
Getting marker list in dictionary format: {cluster: marker_list}
[4]:
markers = pd.read_csv("../demo_data/marker_list.csv")
markers_dict = utils.prepare_markers(markers, "clusterName", "markers")
markers_dict
[4]:
{'e1_e299_SLC17A7_L5b_Cdh13': ['SLC17A7', 'CDH13'],
'g1_g48_GLI3_Astro_Gja1': ['GLI3', 'GJA1'],
'g2_g27_APBB1IP_Micro_Ctss': ['APBB1IP', 'CTSS'],
'g3_g18_GPNMB_OPC_Pdgfra': ['GPNMB', 'PDGFRA'],
'g4_g9_MOG_Oligo_Opalin': ['MOG', 'OPALIN'],
'i10_i16_TSPAN12_Vip_Mybpc1': ['TSPAN12', 'VIP', 'MYBPC1'],
'i11_i6_EGF_Vip_Mybpc1': ['EGF', 'VIP', 'MYBPC1'],
'i1_i90_COL5A2_Ndnf_Car4': ['COL5A2', 'NDNF', 'CAR4'],
'i2_i77_LHX6_Sst_Cbln4': ['LHX6', 'SST', 'CBLN4'],
'i3_i56_BAGE2_Ndnf_Cxcl14': ['BAGE2', 'NDNF', 'CXCL14'],
'i4_i54_MC4R_Ndnf_Cxcl14': ['MC4R', 'NDNF', 'CXCL14'],
'i5_i47_TRPC3_Ndnf_Car4': ['TRPC3', 'NDNF', 'CAR4'],
'i6_i44_GPR149_Vip_Mybpc1': ['GPR149', 'VIP', 'MYBPC1'],
'i7_i31_CLMP_Ndnf_Cxcl14': ['CLMP', 'NDNF', 'CXCL14'],
'i8_i27_SNCG_Vip_Mybpc1': ['SNCG', 'VIP', 'MYBPC1'],
'i9_i22_TAC3_Vip_Mybpc1': ['TAC3', 'VIP', 'MYBPC1']}
[5]:
outputfilename_prefix = "marker_eval"
evaluation_results = ns.ev.DecisionTree(adata, cluster_header, markers_dict, combinations = False, use_mean = False,
save_supplementary = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Running NS-Forest version 4.1
Preparing data...
--- 0.005011320114135742 seconds ---
Number of clusters to evaluate: 16
1 out of 16:
e1_e299_SLC17A7_L5b_Cdh13
marker genes to be evaluated: ['SLC17A7', 'CDH13']
fbeta: 0.945
precision: 0.988
recall: 0.806
2 out of 16:
g1_g48_GLI3_Astro_Gja1
marker genes to be evaluated: ['GLI3', 'GJA1']
fbeta: 0.893
precision: 1.0
recall: 0.625
3 out of 16:
g2_g27_APBB1IP_Micro_Ctss
marker genes to be evaluated: ['APBB1IP', 'CTSS']
fbeta: 0.385
precision: 1.0
recall: 0.111
4 out of 16:
g3_g18_GPNMB_OPC_Pdgfra
marker genes to be evaluated: ['GPNMB', 'PDGFRA']
fbeta: 0.929
precision: 1.0
recall: 0.722
5 out of 16:
g4_g9_MOG_Oligo_Opalin
marker genes to be evaluated: ['MOG', 'OPALIN']
fbeta: 0.909
precision: 1.0
recall: 0.667
6 out of 16:
i10_i16_TSPAN12_Vip_Mybpc1
marker genes to be evaluated: ['TSPAN12', 'VIP', 'MYBPC1']
fbeta: 0.469
precision: 0.75
recall: 0.188
7 out of 16:
i11_i6_EGF_Vip_Mybpc1
marker genes to be evaluated: ['EGF', 'VIP', 'MYBPC1']
fbeta: 0.0
precision: 0.0
recall: 0.0
8 out of 16:
i1_i90_COL5A2_Ndnf_Car4
marker genes to be evaluated: ['COL5A2', 'NDNF', 'CAR4']
warning: cannot find CAR4 in adata.var_names, excluding from DecisionTree.
fbeta: 0.88
precision: 0.94
recall: 0.7
9 out of 16:
i2_i77_LHX6_Sst_Cbln4
marker genes to be evaluated: ['LHX6', 'SST', 'CBLN4']
fbeta: 0.118
precision: 1.0
recall: 0.026
10 out of 16:
i3_i56_BAGE2_Ndnf_Cxcl14
marker genes to be evaluated: ['BAGE2', 'NDNF', 'CXCL14']
fbeta: 0.565
precision: 0.824
recall: 0.25
11 out of 16:
i4_i54_MC4R_Ndnf_Cxcl14
marker genes to be evaluated: ['MC4R', 'NDNF', 'CXCL14']
fbeta: 0.719
precision: 0.913
recall: 0.389
12 out of 16:
i5_i47_TRPC3_Ndnf_Car4
marker genes to be evaluated: ['TRPC3', 'NDNF', 'CAR4']
warning: cannot find CAR4 in adata.var_names, excluding from DecisionTree.
fbeta: 0.0
precision: 0.0
recall: 0.0
13 out of 16:
i6_i44_GPR149_Vip_Mybpc1
marker genes to be evaluated: ['GPR149', 'VIP', 'MYBPC1']
fbeta: 0.188
precision: 0.333
recall: 0.068
14 out of 16:
i7_i31_CLMP_Ndnf_Cxcl14
marker genes to be evaluated: ['CLMP', 'NDNF', 'CXCL14']
fbeta: 0.355
precision: 0.355
recall: 0.355
15 out of 16:
i8_i27_SNCG_Vip_Mybpc1
marker genes to be evaluated: ['SNCG', 'VIP', 'MYBPC1']
fbeta: 0.0
precision: 0.0
recall: 0.0
16 out of 16:
i9_i22_TAC3_Vip_Mybpc1
marker genes to be evaluated: ['TAC3', 'VIP', 'MYBPC1']
fbeta: 0.526
precision: 1.0
recall: 0.182
--- 0.54738450050354 seconds ---
using median
Calculating medians per cluster: 100%|██████████| 16/16 [00:00<00:00, 400.02it/s]
Saving supplementary table as...
../outputs_layer1/marker_eval_markers_onTarget_supp.csv
Saving supplementary table as...
../outputs_layer1/marker_eval_markers_onTarget.csv
[6]:
evaluation_results
[6]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | markers | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.945098 | 0.987705 | 0.806020 | 569 | 3 | 58 | 241 | 2 | [SLC17A7, CDH13] | 0.548527 |
| 1 | 4.1 | cluster | g1_g48_GLI3_Astro_Gja1 | 48 | 0.892857 | 1.000000 | 0.625000 | 823 | 0 | 18 | 30 | 2 | [GLI3, GJA1] | 0.854088 |
| 2 | 4.1 | cluster | g2_g27_APBB1IP_Micro_Ctss | 27 | 0.384615 | 1.000000 | 0.111111 | 844 | 0 | 24 | 3 | 2 | [APBB1IP, CTSS] | 0.955321 |
| 3 | 4.1 | cluster | g3_g18_GPNMB_OPC_Pdgfra | 18 | 0.928571 | 1.000000 | 0.722222 | 853 | 0 | 5 | 13 | 2 | [GPNMB, PDGFRA] | 0.680299 |
| 4 | 4.1 | cluster | g4_g9_MOG_Oligo_Opalin | 9 | 0.909091 | 1.000000 | 0.666667 | 862 | 0 | 3 | 6 | 2 | [MOG, OPALIN] | 1.000000 |
| 5 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.468750 | 0.750000 | 0.187500 | 854 | 1 | 13 | 3 | 3 | [TSPAN12, VIP, MYBPC1] | 0.209097 |
| 6 | 4.1 | cluster | i11_i6_EGF_Vip_Mybpc1 | 6 | 0.000000 | 0.000000 | 0.000000 | 865 | 0 | 6 | 0 | 3 | [EGF, VIP, MYBPC1] | 0.112842 |
| 7 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.879888 | 0.940299 | 0.700000 | 777 | 4 | 27 | 63 | 2 | [COL5A2, NDNF] | 0.608344 |
| 8 | 4.1 | cluster | i2_i77_LHX6_Sst_Cbln4 | 77 | 0.117647 | 1.000000 | 0.025974 | 794 | 0 | 75 | 2 | 3 | [LHX6, SST, CBLN4] | 0.420224 |
| 9 | 4.1 | cluster | i3_i56_BAGE2_Ndnf_Cxcl14 | 56 | 0.564516 | 0.823529 | 0.250000 | 812 | 3 | 42 | 14 | 3 | [BAGE2, NDNF, CXCL14] | 0.103398 |
| 10 | 4.1 | cluster | i4_i54_MC4R_Ndnf_Cxcl14 | 54 | 0.719178 | 0.913043 | 0.388889 | 815 | 2 | 33 | 21 | 3 | [MC4R, NDNF, CXCL14] | 0.351766 |
| 11 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.000000 | 0.000000 | 0.000000 | 803 | 21 | 47 | 0 | 2 | [TRPC3, NDNF] | 0.292197 |
| 12 | 4.1 | cluster | i6_i44_GPR149_Vip_Mybpc1 | 44 | 0.187500 | 0.333333 | 0.068182 | 821 | 6 | 41 | 3 | 3 | [GPR149, VIP, MYBPC1] | 0.235686 |
| 13 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.354839 | 0.354839 | 0.354839 | 820 | 20 | 20 | 11 | 3 | [CLMP, NDNF, CXCL14] | 0.180560 |
| 14 | 4.1 | cluster | i8_i27_SNCG_Vip_Mybpc1 | 27 | 0.000000 | 0.000000 | 0.000000 | 844 | 0 | 27 | 0 | 3 | [SNCG, VIP, MYBPC1] | 0.153438 |
| 15 | 4.1 | cluster | i9_i22_TAC3_Vip_Mybpc1 | 22 | 0.526316 | 1.000000 | 0.181818 | 849 | 0 | 18 | 4 | 3 | [TAC3, VIP, MYBPC1] | 0.288938 |
Plotting scanpy dot plot, violin plot, matrix plot for input marker list
Note: Assign pre-defined dendrogram order here or use adata.uns["dendrogram_" + cluster_header]["categories_ordered"].
[7]:
dendrogram = [] # custom dendrogram order
dendrogram = list(adata.uns["dendrogram_" + cluster_header]["categories_ordered"])
to_plot = evaluation_results.copy()
to_plot["clusterName"] = to_plot["clusterName"].astype("category")
to_plot["clusterName"] = to_plot["clusterName"].cat.set_categories(dendrogram)
to_plot = to_plot.sort_values("clusterName").reset_index(drop = True)
to_plot = to_plot.rename(columns = {"NSForest_markers": "markers"})
[8]:
markers_dict = dict(zip(to_plot["clusterName"], to_plot["markers"]))
markers_dict
[8]:
{'e1_e299_SLC17A7_L5b_Cdh13': ['SLC17A7', 'CDH13'],
'i2_i77_LHX6_Sst_Cbln4': ['LHX6', 'SST', 'CBLN4'],
'g1_g48_GLI3_Astro_Gja1': ['GLI3', 'GJA1'],
'g3_g18_GPNMB_OPC_Pdgfra': ['GPNMB', 'PDGFRA'],
'g2_g27_APBB1IP_Micro_Ctss': ['APBB1IP', 'CTSS'],
'g4_g9_MOG_Oligo_Opalin': ['MOG', 'OPALIN'],
'i7_i31_CLMP_Ndnf_Cxcl14': ['CLMP', 'NDNF', 'CXCL14'],
'i1_i90_COL5A2_Ndnf_Car4': ['COL5A2', 'NDNF'],
'i5_i47_TRPC3_Ndnf_Car4': ['TRPC3', 'NDNF'],
'i11_i6_EGF_Vip_Mybpc1': ['EGF', 'VIP', 'MYBPC1'],
'i3_i56_BAGE2_Ndnf_Cxcl14': ['BAGE2', 'NDNF', 'CXCL14'],
'i10_i16_TSPAN12_Vip_Mybpc1': ['TSPAN12', 'VIP', 'MYBPC1'],
'i4_i54_MC4R_Ndnf_Cxcl14': ['MC4R', 'NDNF', 'CXCL14'],
'i9_i22_TAC3_Vip_Mybpc1': ['TAC3', 'VIP', 'MYBPC1'],
'i6_i44_GPR149_Vip_Mybpc1': ['GPR149', 'VIP', 'MYBPC1'],
'i8_i27_SNCG_Vip_Mybpc1': ['SNCG', 'VIP', 'MYBPC1']}
[9]:
ns.pl.dotplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
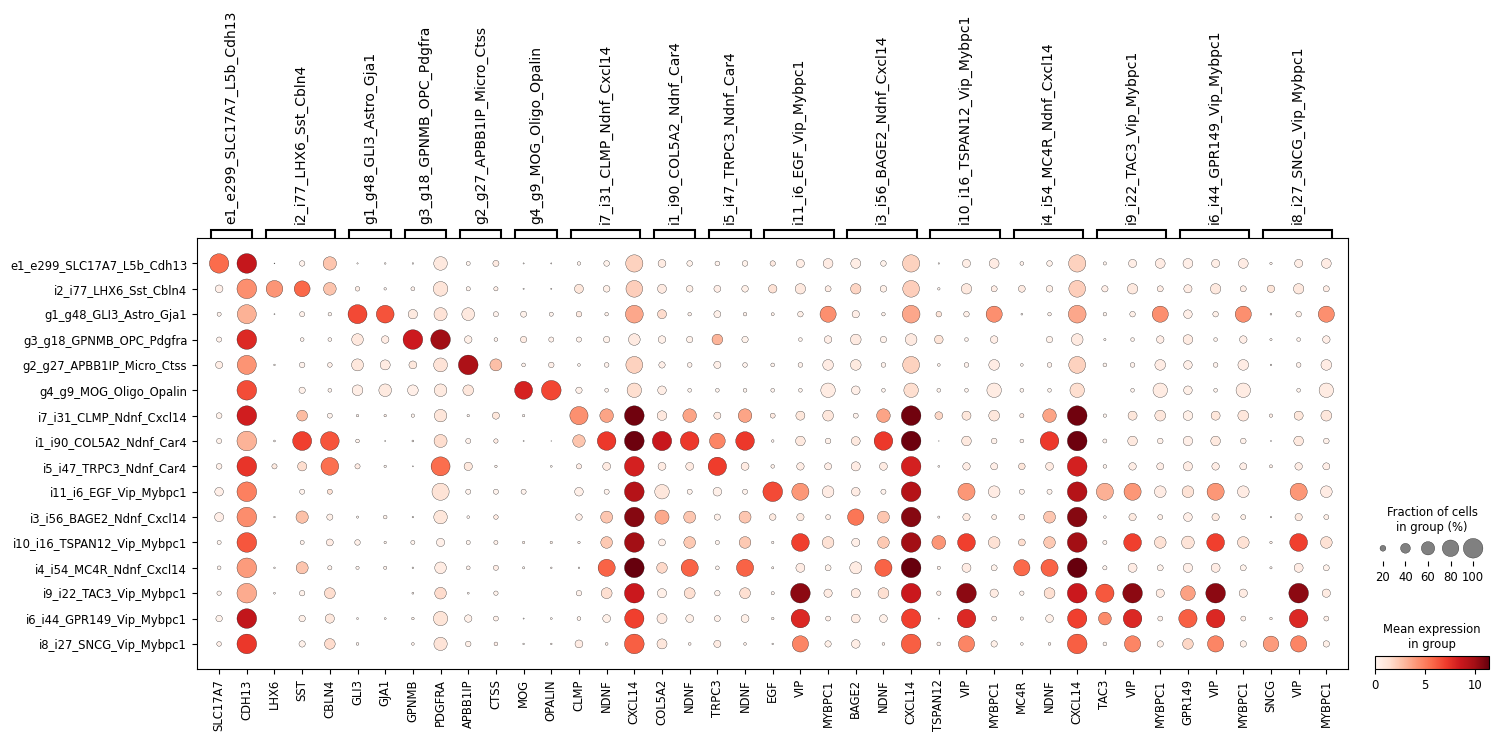
[10]:
ns.pl.stackedviolin(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
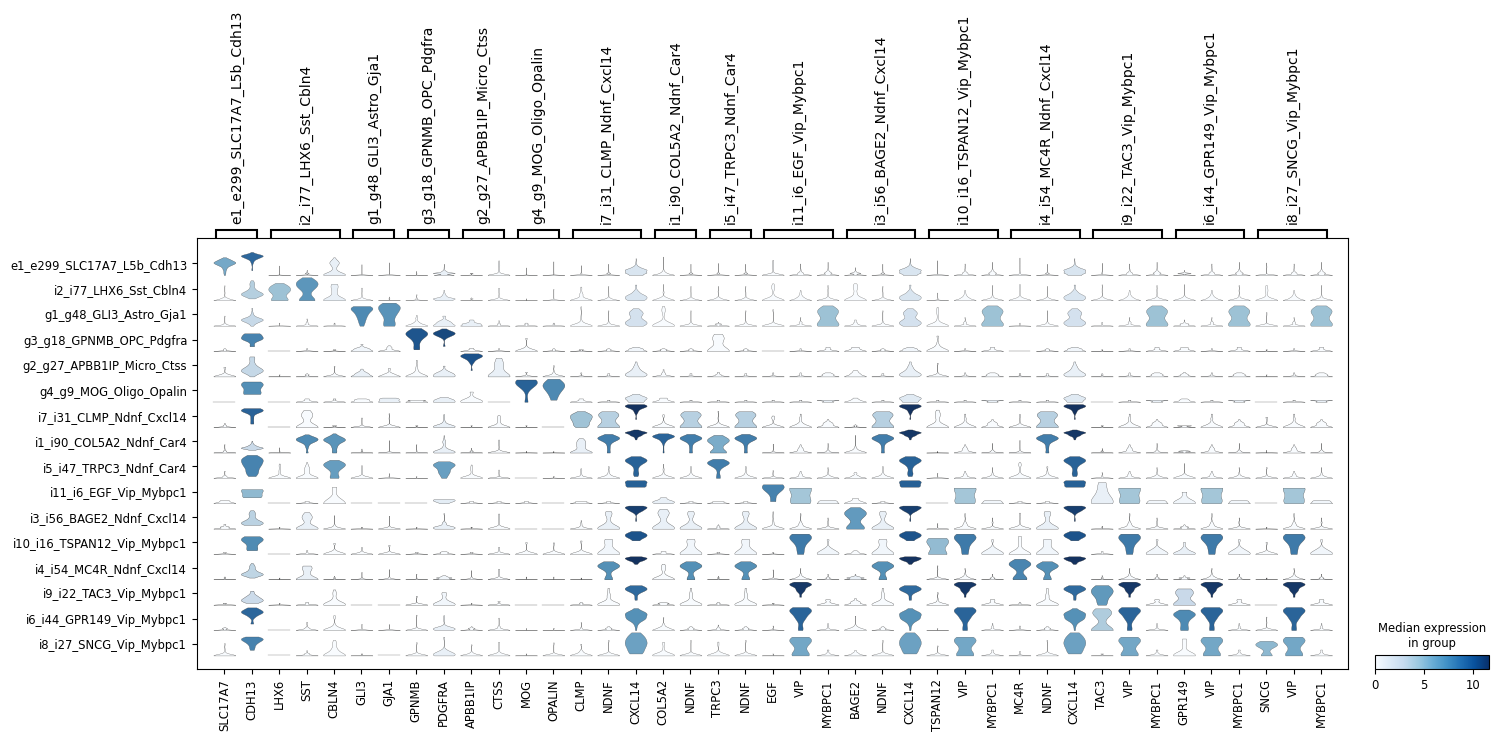
[11]:
ns.pl.matrixplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
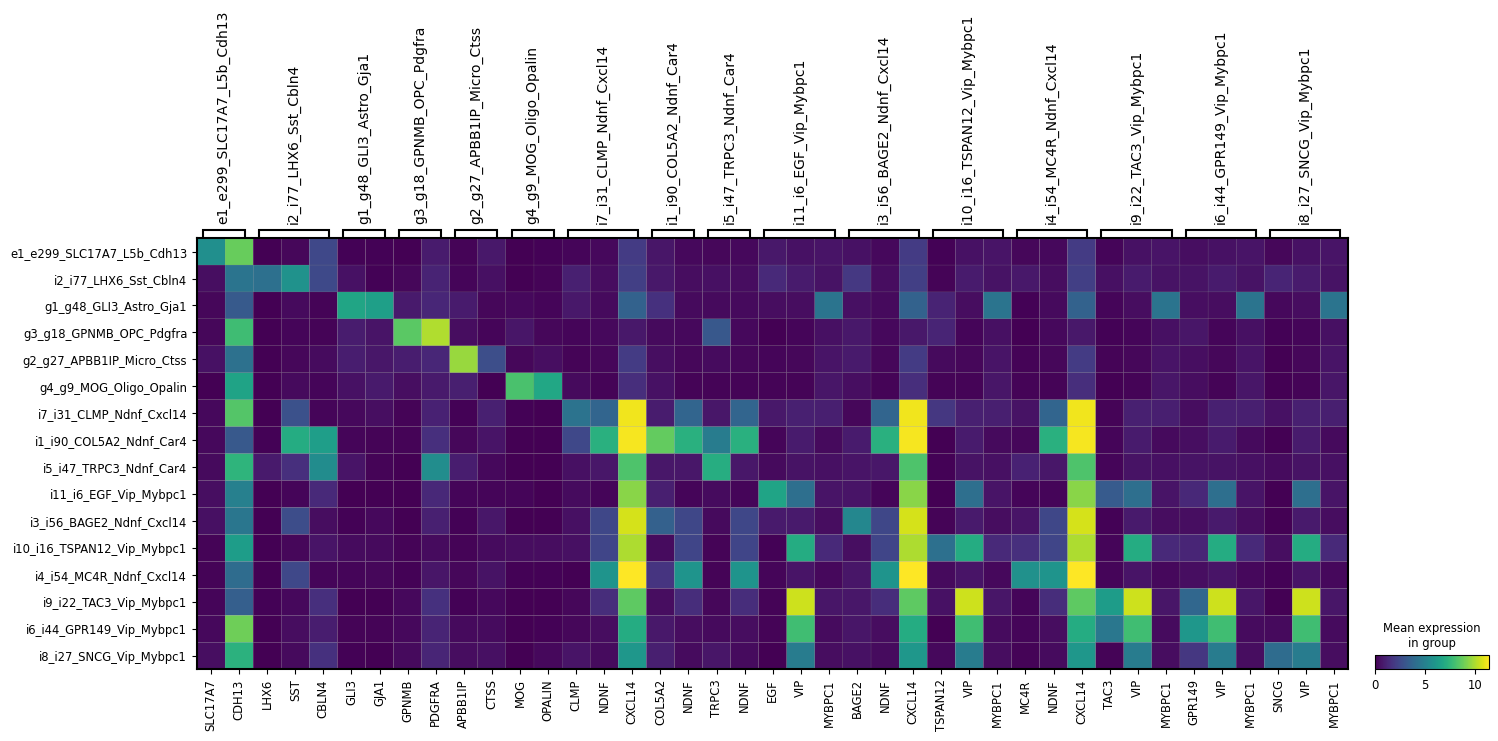
Plotting classification metrics from NS-Forest results
[12]:
ns.pl.boxplot(evaluation_results, ["f_score", "precision", "recall", "onTarget"], save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_boxplot_f_score_precision_recall_onTarget.html
Plotting individual classification metrics
[13]:
ns.pl.boxplot(evaluation_results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_boxplot_f_score.html
Plotting metrics vs clusterSize
[14]:
ns.pl.scatter_w_clusterSize(evaluation_results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_scatter_f_score.html
[15]:
ns.pl.scatter_w_clusterSize(evaluation_results, "precision", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_scatter_precision.html
[16]:
ns.pl.scatter_w_clusterSize(evaluation_results, "recall", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_scatter_recall.html
[17]:
ns.pl.scatter_w_clusterSize(evaluation_results, "onTarget", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../outputs_layer1/marker_eval_scatter_onTarget.html