Tutorial
Tutorial
Setting up environment
[1]:
import sys
import os
import numpy as np
import pandas as pd
import scanpy as sc
import matplotlib.pyplot as plt
CODE_PATH = "../.." # location of NSForest folder
sys.path.insert(0, os.path.abspath(CODE_PATH))
from nsforest import ns, nsforesting, utils, NSFOREST_VERSION
Data Exploration
Loading h5ad AnnData file
[2]:
data_folder = f"{CODE_PATH}/demo_data/"
file = data_folder + "adata_layer1.h5ad"
adata = sc.read_h5ad(file)
adata
[2]:
AnnData object with n_obs × n_vars = 871 × 16497
obs: 'cluster'
Defining cluster_header as cell type annotation.
Note: Some datasets have multiple annotations per sample (ex. “broad_cell_type” and “granular_cell_type”). NS-Forest can be run on multiple cluster_header’s. Combining the parent and child markers may improve classification results.
[3]:
cluster_header = "cluster"
Defining output_folder for saving results
[4]:
output_folder = f"{CODE_PATH}/outputs_layer1/"
Looking at sample labels
[5]:
adata.obs_names
[5]:
Index(['A01_1_Nuclei_NeuNP_H200_1025_MTG_layer1_BCH9',
'A01_BCH3_1NeuNP_H200.1030_MTG_Layer_1',
'A02_BCH1_1NeuNP_H200.1025_MTG_layer_1',
'A03_1_Nuclei_NeuNP_H200_1025_MTG_layer1_BCH9',
'A04_1_Nuclei_NeuNP_H200_1025_MTG_layer1_BCH9',
'A04_BCH1_1NeuNP_H200.1025_MTG_layer_1',
'A04_BCH3_1NeuNP_H200.1030_MTG_Layer_1',
'A05_1_Nuclei_NeuNP_H200_1025_MTG_layer1_BCH9',
'A05_BCH1_1NeuNP_H200.1025_MTG_layer_1',
'A05_BCH3_1NeuNP_H200.1030_MTG_Layer_1',
...
'P09_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH7',
'P09_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH9',
'P09_1_Nuclei_NeuNN_H200_1030_MTG_layer1_BCH8',
'P09_BCH1_1NeuNN_H200.1025_MTG_layer_1',
'P10_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH6',
'P10_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH9',
'P10_BCH1_1NeuNN_H200.1025_MTG_layer_1',
'P11_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH7',
'P11_1_Nuclei_NeuNN_H200_1025_MTG_layer1_BCH9',
'P11_1_Nuclei_NeuNN_H200_1030_MTG_layer1_BCH8'],
dtype='object', length=871)
Looking at genes
Note: adata.var_names must be unique. If there is a problem, usually it can be solved by assigning adata.var.index = adata.var["ensembl_id"].
[6]:
adata.var_names
[6]:
Index(['A1CF', 'A2M', 'A2M_AS1', 'A2ML1', 'A2ML1_AS1', 'A2MP1', 'A3GALT2',
'A4GALT', 'AAAS', 'AACS',
...
'ZUFSP', 'ZW10', 'ZWILCH', 'ZWINT', 'ZXDC', 'ZYG11A', 'ZYG11B', 'ZYX',
'ZZEF1', 'ZZZ3'],
dtype='object', length=16497)
Checking cell annotation sizes
Note: Some datasets are too large and need to be downsampled to be run through the pipeline. When downsampling, be sure to have all the granular cluster annotations represented.
[7]:
adata.obs[cluster_header].value_counts()
[7]:
e1_e299_SLC17A7_L5b_Cdh13 299
i1_i90_COL5A2_Ndnf_Car4 90
i2_i77_LHX6_Sst_Cbln4 77
i3_i56_BAGE2_Ndnf_Cxcl14 56
i4_i54_MC4R_Ndnf_Cxcl14 54
g1_g48_GLI3_Astro_Gja1 48
i5_i47_TRPC3_Ndnf_Car4 47
i6_i44_GPR149_Vip_Mybpc1 44
i7_i31_CLMP_Ndnf_Cxcl14 31
g2_g27_APBB1IP_Micro_Ctss 27
i8_i27_SNCG_Vip_Mybpc1 27
i9_i22_TAC3_Vip_Mybpc1 22
g3_g18_GPNMB_OPC_Pdgfra 18
i10_i16_TSPAN12_Vip_Mybpc1 16
g4_g9_MOG_Oligo_Opalin 9
i11_i6_EGF_Vip_Mybpc1 6
Name: cluster, dtype: int64
Preprocessing
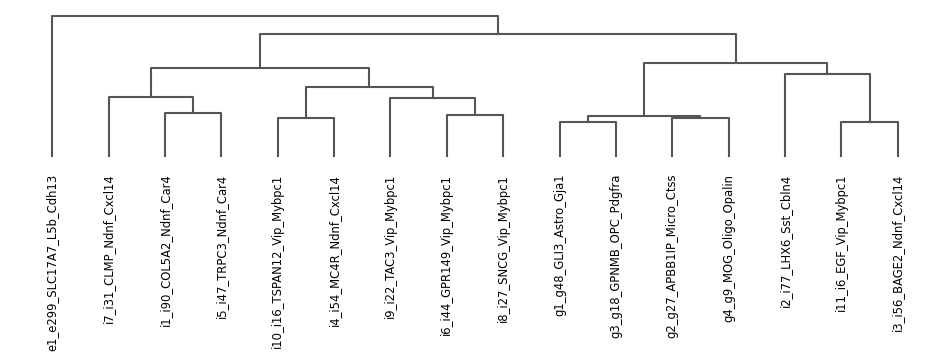
Generating scanpy dendrogram
Note: Only run if there is no pre-defined dendrogram order. Dendrogram order is stored in adata.uns["dendrogram_cluster"]["categories_ordered"].
You can add additional arguments into ns.pp.dendrogram() that can be passed into the scanpy dendrogram function. Ex: ns.pp.dendrogram(adata, cluster_header, orientation = “bottom”)
[8]:
ns.pp.dendrogram(adata, cluster_header, save = True, output_folder = output_folder, outputfilename_suffix = cluster_header)
WARNING: You’re trying to run this on 16497 dimensions of `.X`, if you really want this, set `use_rep='X'`.
Falling back to preprocessing with `sc.pp.pca` and default params.
C:\Users\bpeng\AppData\Local\anaconda3\Lib\site-packages\anndata\_core\anndata.py:522: FutureWarning: The dtype argument is deprecated and will be removed in late 2024.
warnings.warn(
WARNING: saving figure to file ..\..\outputs_layer1\dendrogram_cluster.png
Calculating cluster medians per gene
Run ns.pp.prep_medians before running NS-Forest.
Note: Do not run if evaluating marker lists. Do not run before generating scanpy plots (e.g. dot plot, violin plot, matrix plot). This step removes genes from adata. The full adata should be used for evaluating and plotting.
[9]:
adata_subset = adata.copy()
[10]:
adata_subset = ns.pp.prep_medians(adata_subset, cluster_header)
adata_subset
Calculating medians...
Calculating medians (means) per cluster: 100%|██████████| 16/16 [00:00<00:00, 57.19it/s]
Saving calculated medians as adata.varm.medians_cluster
--- 0.28774333000183105 seconds ---
median: 0.0
mean: 1.62611
std: 2.488900899887085
Only positive genes selected. 11688 positive genes out of 16497 total genes
[10]:
AnnData object with n_obs × n_vars = 871 × 11688
obs: 'cluster'
uns: 'dendrogram_cluster'
obsm: 'X_pca'
varm: 'medians_cluster'
Calculating binary scores per gene per cluster
Run ns.pp.prep_binary_scores before running NS-Forest. Do not need to run if evaluating marker lists. Do not need to run when generating scanpy plots.
[11]:
adata_subset = ns.pp.prep_binary_scores(adata_subset, cluster_header)
adata_subset
Calculating binary scores...
Calculating binary scores per cluster: 100%|██████████| 16/16 [00:53<00:00, 3.36s/it]
Saving calculated binary scores as adata.varm.binary_scores_cluster
--- 54.23224496841431 seconds ---
median: 0.1
mean: 0.2016436226562706
std: 0.25240082537940856
[11]:
AnnData object with n_obs × n_vars = 871 × 11688
obs: 'cluster'
uns: 'dendrogram_cluster'
obsm: 'X_pca'
varm: 'medians_cluster', 'binary_scores_cluster'
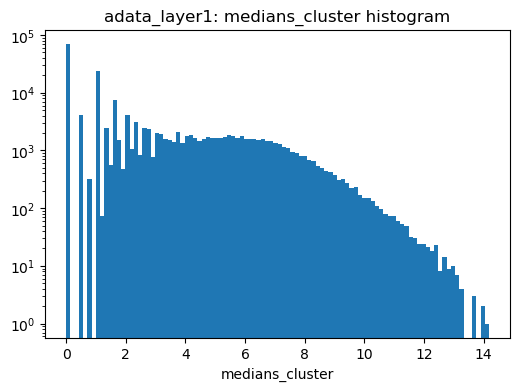
Plotting median and binary score distributions
[12]:
plt.clf()
filename = output_folder + cluster_header + '_medians.png'
print(f"Saving median distributions as...\n{filename}")
a = plt.figure(figsize = (6, 4))
a = plt.hist(adata_subset.varm["medians_" + cluster_header].unstack(), bins = 100)
a = plt.title(f'{file.split("/")[-1].replace(".h5ad", "")}: {"medians_" + cluster_header} histogram')
a = plt.xlabel("medians_" + cluster_header)
a = plt.yscale("log")
a = plt.savefig(filename, bbox_inches='tight')
plt.show()
Saving median distributions as...
../../outputs_layer1/cluster_medians.png
<Figure size 640x480 with 0 Axes>
[13]:
plt.clf()
filename = output_folder + cluster_header + '_binary_scores.png'
print(f"Saving binary_score distributions as...\n{filename}")
a = plt.figure(figsize = (6, 4))
a = plt.hist(adata_subset.varm["binary_scores_" + cluster_header].unstack(), bins = 100)
a = plt.title(f'{file.split("/")[-1].replace(".h5ad", "")}: {"binary_scores_" + cluster_header} histogram')
a = plt.xlabel("binary_scores_" + cluster_header)
a = plt.yscale("log")
a = plt.savefig(filename, bbox_inches='tight')
plt.show()
Saving binary_score distributions as...
../../outputs_layer1/cluster_binary_scores.png
<Figure size 640x480 with 0 Axes>

Saving preprocessed AnnData as new h5ad
[14]:
# Optional, can be useful if you don't want to re-run prep_medians and prep_binary_scores
filename = file.replace(".h5ad", "_preprocessed.h5ad")
print(f"Saving new anndata object as...\n{filename}")
adata_subset.write_h5ad(filename)
adata_subset
Saving new anndata object as...
../../demo_data/adata_layer1_preprocessed.h5ad
[14]:
AnnData object with n_obs × n_vars = 871 × 11688
obs: 'cluster'
uns: 'dendrogram_cluster'
obsm: 'X_pca'
varm: 'medians_cluster', 'binary_scores_cluster'
Running NS-Forest
Note: Do not run NS-Forest if only evaluating input marker lists.
[15]:
outputfilename_prefix = cluster_header
results = nsforesting.NSForest(adata_subset, cluster_header, save = True, save_supplementary = True,
output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Running NS-Forest version 4.1
Preparing adata...
--- 0.007977008819580078 seconds ---
Pre-selecting genes based on binary scores...
BinaryFirst_high Threshold (mean + 2 * std): 0.7064452734150877
Average number of genes after gene_selection in each cluster: 735.5
Saving number of genes selected per cluster as...
../../outputs_layer1/cluster_gene_selection.csv
Number of clusters to evaluate: 16
1 out of 16:
e1_e299_SLC17A7_L5b_Cdh13
Pre-selected 1356 genes to feed into Random Forest.
NSForest-selected markers: ['LINC00507']
fbeta: 0.96
precision: 0.978
recall: 0.893
2 out of 16:
g1_g48_GLI3_Astro_Gja1
Pre-selected 583 genes to feed into Random Forest.
NSForest-selected markers: ['LINC00498']
fbeta: 0.95
precision: 1.0
recall: 0.792
3 out of 16:
g2_g27_APBB1IP_Micro_Ctss
Pre-selected 420 genes to feed into Random Forest.
NSForest-selected markers: ['ADAM28', 'PTPRC']
fbeta: 0.976
precision: 1.0
recall: 0.889
4 out of 16:
g3_g18_GPNMB_OPC_Pdgfra
Pre-selected 353 genes to feed into Random Forest.
NSForest-selected markers: ['GPNMB', 'OLIG2']
fbeta: 0.862
precision: 1.0
recall: 0.556
5 out of 16:
g4_g9_MOG_Oligo_Opalin
Pre-selected 571 genes to feed into Random Forest.
NSForest-selected markers: ['ST18']
fbeta: 1.0
precision: 1.0
recall: 1.0
6 out of 16:
i10_i16_TSPAN12_Vip_Mybpc1
Pre-selected 1007 genes to feed into Random Forest.
NSForest-selected markers: ['TSPAN12', 'CHRNB3']
fbeta: 0.804
precision: 0.9
recall: 0.562
7 out of 16:
i11_i6_EGF_Vip_Mybpc1
Pre-selected 1912 genes to feed into Random Forest.
NSForest-selected markers: ['EGF', 'FBRSL1']
fbeta: 0.714
precision: 1.0
recall: 0.333
8 out of 16:
i1_i90_COL5A2_Ndnf_Car4
Pre-selected 238 genes to feed into Random Forest.
NSForest-selected markers: ['COL5A2', 'BMP6']
fbeta: 0.908
precision: 0.97
recall: 0.722
9 out of 16:
i2_i77_LHX6_Sst_Cbln4
Pre-selected 292 genes to feed into Random Forest.
NSForest-selected markers: ['LHX6']
fbeta: 0.817
precision: 0.838
recall: 0.74
10 out of 16:
i3_i56_BAGE2_Ndnf_Cxcl14
Pre-selected 151 genes to feed into Random Forest.
NSForest-selected markers: ['BAGE2', 'SYT10']
fbeta: 0.781
precision: 0.962
recall: 0.446
11 out of 16:
i4_i54_MC4R_Ndnf_Cxcl14
Pre-selected 223 genes to feed into Random Forest.
NSForest-selected markers: ['ARHGAP36', 'ADAM33']
fbeta: 0.857
precision: 0.923
recall: 0.667
12 out of 16:
i5_i47_TRPC3_Ndnf_Car4
Pre-selected 942 genes to feed into Random Forest.
NSForest-selected markers: ['NTNG1', 'EYA4']
fbeta: 0.906
precision: 1.0
recall: 0.66
13 out of 16:
i6_i44_GPR149_Vip_Mybpc1
Pre-selected 377 genes to feed into Random Forest.
NSForest-selected markers: ['FLT1', 'GPR149']
fbeta: 0.792
precision: 1.0
recall: 0.432
14 out of 16:
i7_i31_CLMP_Ndnf_Cxcl14
Pre-selected 1012 genes to feed into Random Forest.
NSForest-selected markers: ['PAX6', 'TGFBR2']
fbeta: 0.901
precision: 1.0
recall: 0.645
15 out of 16:
i8_i27_SNCG_Vip_Mybpc1
Pre-selected 1326 genes to feed into Random Forest.
NSForest-selected markers: ['SNCG', 'EDNRA']
fbeta: 0.759
precision: 0.923
recall: 0.444
16 out of 16:
i9_i22_TAC3_Vip_Mybpc1
Pre-selected 1005 genes to feed into Random Forest.
NSForest-selected markers: ['BSPRY', 'MCTP2']
fbeta: 0.69
precision: 0.889
recall: 0.364
Saving supplementary table as...
../../outputs_layer1/cluster_supplementary.csv
Saving markers table as...
../../outputs_layer1/cluster_markers.csv
using mean
Calculating medians (means) per cluster: 100%|██████████| 16/16 [00:00<00:00, 314.34it/s]
Saving supplementary table as...
../../outputs_layer1/cluster_markers_onTarget_supp.csv
Saving supplementary table as...
../../outputs_layer1/cluster_markers_onTarget.csv
Saving final results table as...
../../outputs_layer1/cluster_results.csv
Saving final results table as...
../../outputs_layer1/cluster_results.pkl
--- 63.96290040016174 seconds ---
[16]:
results
[16]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | NSForest_markers | binary_genes | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.959741 | 0.978022 | 0.892977 | 566 | 6 | 32 | 267 | 1 | [LINC00507] | [SLC17A7, LINC00508, TBR1, ANKRD33B, NPTX1, LI... | 0.479336 |
| 1 | 4.1 | cluster | g1_g48_GLI3_Astro_Gja1 | 48 | 0.950000 | 1.000000 | 0.791667 | 823 | 0 | 10 | 38 | 1 | [LINC00498] | [LINC00498, SLC25A18, EMX2OS, FAM189A2, SLC7A1... | 0.882322 |
| 2 | 4.1 | cluster | g2_g27_APBB1IP_Micro_Ctss | 27 | 0.975610 | 1.000000 | 0.888889 | 844 | 0 | 3 | 24 | 2 | [ADAM28, PTPRC] | [ADAM28, PLCG2, INPP5D, PTPRC, CSF2RA, P2RY13,... | 0.736514 |
| 3 | 4.1 | cluster | g3_g18_GPNMB_OPC_Pdgfra | 18 | 0.862069 | 1.000000 | 0.555556 | 853 | 0 | 8 | 10 | 2 | [GPNMB, OLIG2] | [GPNMB, COL20A1, OLIG2, STK32A, KLRC3, KLRC2, ... | 0.656991 |
| 4 | 4.1 | cluster | g4_g9_MOG_Oligo_Opalin | 9 | 1.000000 | 1.000000 | 1.000000 | 862 | 0 | 0 | 9 | 1 | [ST18] | [ST18, MOBP, CNDP1, MOG, CD22, FOLH1, TF, CARN... | 0.622487 |
| 5 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.803571 | 0.900000 | 0.562500 | 854 | 1 | 7 | 9 | 2 | [TSPAN12, CHRNB3] | [TSPAN12, TMC5, LINC01539, CHRNB3, FAM46A, ANG... | 0.370267 |
| 6 | 4.1 | cluster | i11_i6_EGF_Vip_Mybpc1 | 6 | 0.714286 | 1.000000 | 0.333333 | 865 | 0 | 4 | 2 | 2 | [EGF, FBRSL1] | [EGF, FZD8, KCNJ2_AS1, FBRSL1, TEKT1, NRG3_AS1... | 0.356487 |
| 7 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.907821 | 0.970149 | 0.722222 | 779 | 2 | 25 | 65 | 2 | [COL5A2, BMP6] | [NMBR, COL5A2, C8ORF4, PAPSS2, TRPC3, BMP6, SS... | 0.299027 |
| 8 | 4.1 | cluster | i2_i77_LHX6_Sst_Cbln4 | 77 | 0.816619 | 0.838235 | 0.740260 | 783 | 11 | 20 | 57 | 1 | [LHX6] | [LHX6, FLT3, TAC1, CALB1, RSPO3, TRBC2, GRIK3,... | 0.795864 |
| 9 | 4.1 | cluster | i3_i56_BAGE2_Ndnf_Cxcl14 | 56 | 0.781250 | 0.961538 | 0.446429 | 814 | 1 | 31 | 25 | 2 | [BAGE2, SYT10] | [BAGE2, SCN5A, GREM2, FAM19A4, SYT10, ARHGAP18... | 0.282582 |
| 10 | 4.1 | cluster | i4_i54_MC4R_Ndnf_Cxcl14 | 54 | 0.857143 | 0.923077 | 0.666667 | 814 | 3 | 18 | 36 | 2 | [ARHGAP36, ADAM33] | [ARHGAP36, MC4R, COBLL1, HLA_B, LINC01435, ADA... | 0.394957 |
| 11 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.906433 | 1.000000 | 0.659574 | 824 | 0 | 16 | 31 | 2 | [NTNG1, EYA4] | [SSTR2, KIRREL, TRPC3, NTNG1, TARID, EYA4, CA2... | 0.265959 |
| 12 | 4.1 | cluster | i6_i44_GPR149_Vip_Mybpc1 | 44 | 0.791667 | 1.000000 | 0.431818 | 827 | 0 | 25 | 19 | 2 | [FLT1, GPR149] | [FLT1, PLCE1_AS1, CXCL12, SLC22A3, PLCE1_AS2, ... | 0.455438 |
| 13 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.900901 | 1.000000 | 0.645161 | 840 | 0 | 11 | 20 | 2 | [PAX6, TGFBR2] | [KIAA1644, FGF10, CLMP, PAX6, SP8, TGFBR2, WIF... | 0.364283 |
| 14 | 4.1 | cluster | i8_i27_SNCG_Vip_Mybpc1 | 27 | 0.759494 | 0.923077 | 0.444444 | 843 | 1 | 15 | 12 | 2 | [SNCG, EDNRA] | [SNCG, MMRN2, EDNRA, FBN3, KCNK2, RGS2, SCML4,... | 0.474188 |
| 15 | 4.1 | cluster | i9_i22_TAC3_Vip_Mybpc1 | 22 | 0.689655 | 0.888889 | 0.363636 | 848 | 1 | 14 | 8 | 2 | [BSPRY, MCTP2] | [BSPRY, OFD1P10Y, MCTP2, OFD1P8Y, OFD1P15Y, OF... | 0.467223 |
Plotting classification metrics from NS-Forest results
[17]:
ns.pl.boxplot(results, "f_score", save = "html", output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_boxplot_f_score.html
[18]:
ns.pl.boxplot(results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_boxplot_f_score.html
[19]:
ns.pl.boxplot(results, "precision", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_boxplot_precision.html
[20]:
ns.pl.boxplot(results, "recall", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_boxplot_recall.html
[21]:
ns.pl.boxplot(results, "onTarget", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_boxplot_onTarget.html
[22]:
ns.pl.scatter_w_clusterSize(results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_scatter_f_score.html
[23]:
ns.pl.scatter_w_clusterSize(results, "precision", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_scatter_precision.html
[24]:
ns.pl.scatter_w_clusterSize(results, "recall", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_scatter_recall.html
[25]:
ns.pl.scatter_w_clusterSize(results, "onTarget", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/cluster_scatter_onTarget.html
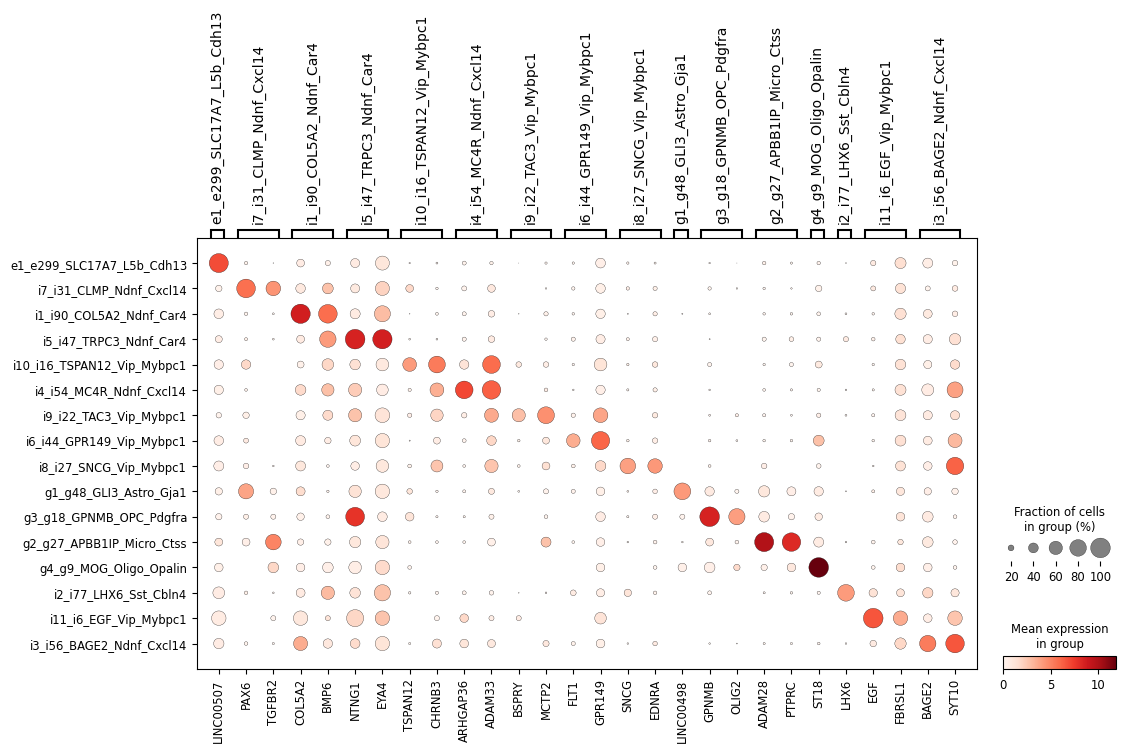
Plotting scanpy dot plot, violin plot, matrix plot for NS-Forest markers
Note: Assign pre-defined dendrogram order here or use adata.uns["dendrogram_" + cluster_header]["categories_ordered"].
Notice how the non-altered adata is used to plot, instead of adata_subset.
[26]:
to_plot = results.copy()
[27]:
dendrogram = [] # custom dendrogram order
dendrogram = list(adata.uns["dendrogram_" + cluster_header]["categories_ordered"])
to_plot["clusterName"] = to_plot["clusterName"].astype("category")
to_plot["clusterName"] = to_plot["clusterName"].cat.set_categories(dendrogram)
to_plot = to_plot.sort_values("clusterName")
to_plot = to_plot.rename(columns = {"NSForest_markers": "markers"})
to_plot.head()
[27]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | markers | binary_genes | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.959741 | 0.978022 | 0.892977 | 566 | 6 | 32 | 267 | 1 | [LINC00507] | [SLC17A7, LINC00508, TBR1, ANKRD33B, NPTX1, LI... | 0.479336 |
| 13 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.900901 | 1.000000 | 0.645161 | 840 | 0 | 11 | 20 | 2 | [PAX6, TGFBR2] | [KIAA1644, FGF10, CLMP, PAX6, SP8, TGFBR2, WIF... | 0.364283 |
| 7 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.907821 | 0.970149 | 0.722222 | 779 | 2 | 25 | 65 | 2 | [COL5A2, BMP6] | [NMBR, COL5A2, C8ORF4, PAPSS2, TRPC3, BMP6, SS... | 0.299027 |
| 11 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.906433 | 1.000000 | 0.659574 | 824 | 0 | 16 | 31 | 2 | [NTNG1, EYA4] | [SSTR2, KIRREL, TRPC3, NTNG1, TARID, EYA4, CA2... | 0.265959 |
| 5 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.803571 | 0.900000 | 0.562500 | 854 | 1 | 7 | 9 | 2 | [TSPAN12, CHRNB3] | [TSPAN12, TMC5, LINC01539, CHRNB3, FAM46A, ANG... | 0.370267 |
[28]:
markers_dict = dict(zip(to_plot["clusterName"], to_plot["markers"]))
markers_dict
[28]:
{'e1_e299_SLC17A7_L5b_Cdh13': ['LINC00507'],
'i7_i31_CLMP_Ndnf_Cxcl14': ['PAX6', 'TGFBR2'],
'i1_i90_COL5A2_Ndnf_Car4': ['COL5A2', 'BMP6'],
'i5_i47_TRPC3_Ndnf_Car4': ['NTNG1', 'EYA4'],
'i10_i16_TSPAN12_Vip_Mybpc1': ['TSPAN12', 'CHRNB3'],
'i4_i54_MC4R_Ndnf_Cxcl14': ['ARHGAP36', 'ADAM33'],
'i9_i22_TAC3_Vip_Mybpc1': ['BSPRY', 'MCTP2'],
'i6_i44_GPR149_Vip_Mybpc1': ['FLT1', 'GPR149'],
'i8_i27_SNCG_Vip_Mybpc1': ['SNCG', 'EDNRA'],
'g1_g48_GLI3_Astro_Gja1': ['LINC00498'],
'g3_g18_GPNMB_OPC_Pdgfra': ['GPNMB', 'OLIG2'],
'g2_g27_APBB1IP_Micro_Ctss': ['ADAM28', 'PTPRC'],
'g4_g9_MOG_Oligo_Opalin': ['ST18'],
'i2_i77_LHX6_Sst_Cbln4': ['LHX6'],
'i11_i6_EGF_Vip_Mybpc1': ['EGF', 'FBRSL1'],
'i3_i56_BAGE2_Ndnf_Cxcl14': ['BAGE2', 'SYT10']}
[29]:
ns.pl.dotplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\dotplot_cluster.png
C:\Users\bpeng\AppData\Local\anaconda3\Lib\site-packages\scanpy\plotting\_dotplot.py:747: UserWarning:
No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
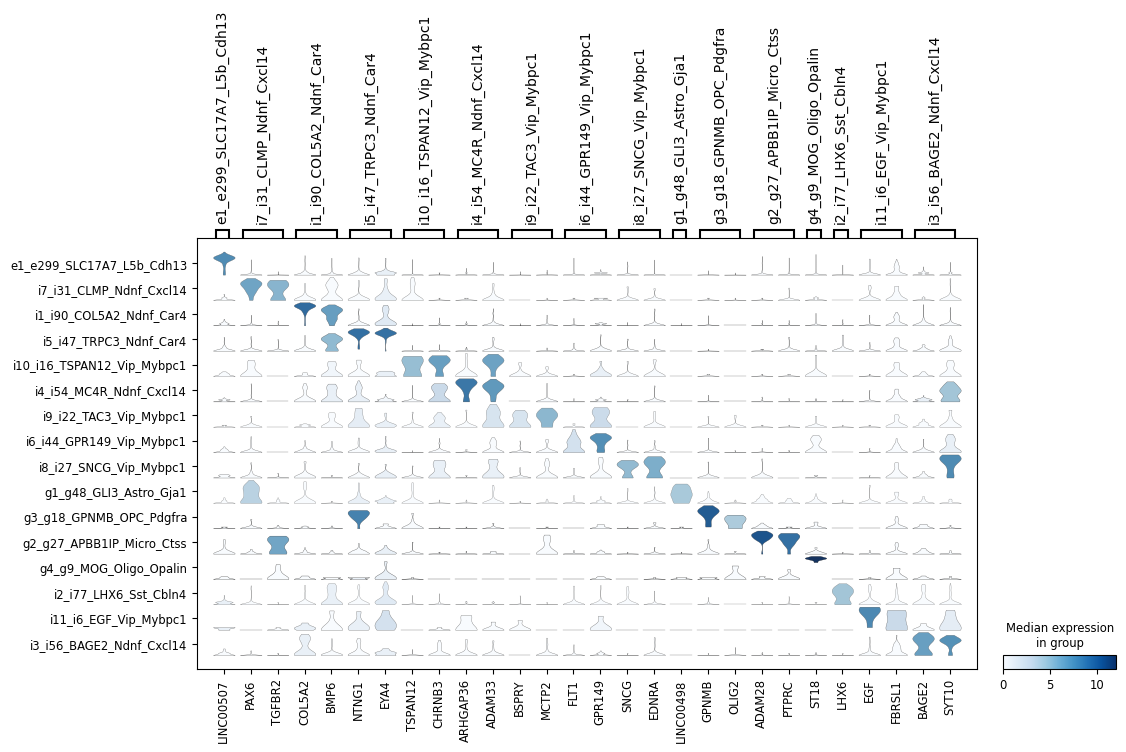
[30]:
ns.pl.stackedviolin(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\stacked_violin_cluster.png
[31]:
ns.pl.matrixplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\matrixplot_cluster.png
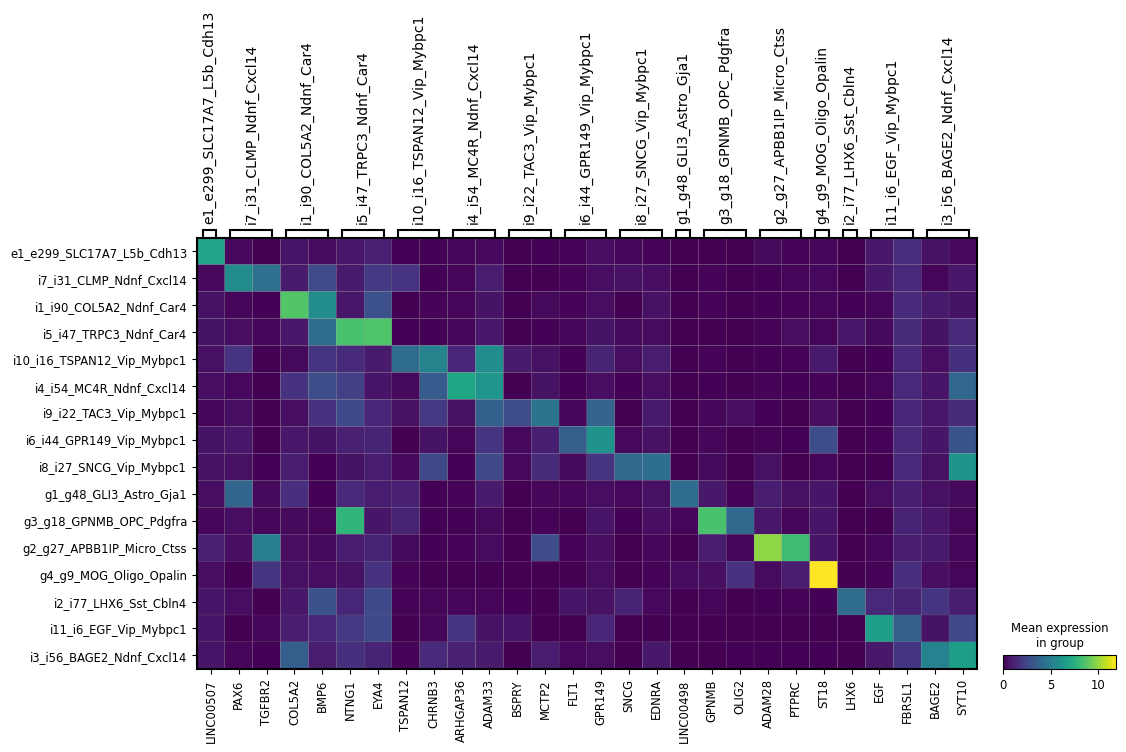
Evaluating input marker list
Getting marker list in dictionary format: {cluster: marker_list}
[32]:
markers = pd.read_csv("../../demo_data/marker_list.csv")
markers_dict = utils.prepare_markers(markers, "clusterName", "markers")
markers_dict
[32]:
{'e1_e299_SLC17A7_L5b_Cdh13': ['SLC17A7', 'CDH13'],
'g1_g48_GLI3_Astro_Gja1': ['GLI3', 'GJA1'],
'g2_g27_APBB1IP_Micro_Ctss': ['APBB1IP', 'CTSS'],
'g3_g18_GPNMB_OPC_Pdgfra': ['GPNMB', 'PDGFRA'],
'g4_g9_MOG_Oligo_Opalin': ['MOG', 'OPALIN'],
'i10_i16_TSPAN12_Vip_Mybpc1': ['TSPAN12', 'VIP', 'MYBPC1'],
'i11_i6_EGF_Vip_Mybpc1': ['EGF', 'VIP', 'MYBPC1'],
'i1_i90_COL5A2_Ndnf_Car4': ['COL5A2', 'NDNF', 'CAR4'],
'i2_i77_LHX6_Sst_Cbln4': ['LHX6', 'SST', 'CBLN4'],
'i3_i56_BAGE2_Ndnf_Cxcl14': ['BAGE2', 'NDNF', 'CXCL14'],
'i4_i54_MC4R_Ndnf_Cxcl14': ['MC4R', 'NDNF', 'CXCL14'],
'i5_i47_TRPC3_Ndnf_Car4': ['TRPC3', 'NDNF', 'CAR4'],
'i6_i44_GPR149_Vip_Mybpc1': ['GPR149', 'VIP', 'MYBPC1'],
'i7_i31_CLMP_Ndnf_Cxcl14': ['CLMP', 'NDNF', 'CXCL14'],
'i8_i27_SNCG_Vip_Mybpc1': ['SNCG', 'VIP', 'MYBPC1'],
'i9_i22_TAC3_Vip_Mybpc1': ['TAC3', 'VIP', 'MYBPC1']}
[33]:
outputfilename_prefix = "marker_eval"
evaluation_results = ns.ev.DecisionTree(adata, cluster_header, markers_dict, combinations = False, use_mean = False,
save = True, save_supplementary = True,
output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Running NS-Forest version 4.1
Preparing data...
--- 0.005984306335449219 seconds ---
Number of clusters to evaluate: 16
1 out of 16:
e1_e299_SLC17A7_L5b_Cdh13
marker genes to be evaluated: ['SLC17A7', 'CDH13']
fbeta: 0.945
precision: 0.988
recall: 0.806
2 out of 16:
g1_g48_GLI3_Astro_Gja1
marker genes to be evaluated: ['GLI3', 'GJA1']
fbeta: 0.893
precision: 1.0
recall: 0.625
3 out of 16:
g2_g27_APBB1IP_Micro_Ctss
marker genes to be evaluated: ['APBB1IP', 'CTSS']
fbeta: 0.385
precision: 1.0
recall: 0.111
4 out of 16:
g3_g18_GPNMB_OPC_Pdgfra
marker genes to be evaluated: ['GPNMB', 'PDGFRA']
fbeta: 0.929
precision: 1.0
recall: 0.722
5 out of 16:
g4_g9_MOG_Oligo_Opalin
marker genes to be evaluated: ['MOG', 'OPALIN']
fbeta: 0.909
precision: 1.0
recall: 0.667
6 out of 16:
i10_i16_TSPAN12_Vip_Mybpc1
marker genes to be evaluated: ['TSPAN12', 'VIP', 'MYBPC1']
fbeta: 0.469
precision: 0.75
recall: 0.188
7 out of 16:
i11_i6_EGF_Vip_Mybpc1
marker genes to be evaluated: ['EGF', 'VIP', 'MYBPC1']
fbeta: 0.0
precision: 0.0
recall: 0.0
8 out of 16:
i1_i90_COL5A2_Ndnf_Car4
marker genes to be evaluated: ['COL5A2', 'NDNF', 'CAR4']
warning: cannot find CAR4 in adata.var_names, excluding from DecisionTree.
fbeta: 0.88
precision: 0.94
recall: 0.7
9 out of 16:
i2_i77_LHX6_Sst_Cbln4
marker genes to be evaluated: ['LHX6', 'SST', 'CBLN4']
fbeta: 0.118
precision: 1.0
recall: 0.026
10 out of 16:
i3_i56_BAGE2_Ndnf_Cxcl14
marker genes to be evaluated: ['BAGE2', 'NDNF', 'CXCL14']
fbeta: 0.565
precision: 0.824
recall: 0.25
11 out of 16:
i4_i54_MC4R_Ndnf_Cxcl14
marker genes to be evaluated: ['MC4R', 'NDNF', 'CXCL14']
fbeta: 0.719
precision: 0.913
recall: 0.389
12 out of 16:
i5_i47_TRPC3_Ndnf_Car4
marker genes to be evaluated: ['TRPC3', 'NDNF', 'CAR4']
warning: cannot find CAR4 in adata.var_names, excluding from DecisionTree.
fbeta: 0.0
precision: 0.0
recall: 0.0
13 out of 16:
i6_i44_GPR149_Vip_Mybpc1
marker genes to be evaluated: ['GPR149', 'VIP', 'MYBPC1']
fbeta: 0.188
precision: 0.333
recall: 0.068
14 out of 16:
i7_i31_CLMP_Ndnf_Cxcl14
marker genes to be evaluated: ['CLMP', 'NDNF', 'CXCL14']
fbeta: 0.355
precision: 0.355
recall: 0.355
15 out of 16:
i8_i27_SNCG_Vip_Mybpc1
marker genes to be evaluated: ['SNCG', 'VIP', 'MYBPC1']
fbeta: 0.0
precision: 0.0
recall: 0.0
16 out of 16:
i9_i22_TAC3_Vip_Mybpc1
marker genes to be evaluated: ['TAC3', 'VIP', 'MYBPC1']
fbeta: 0.526
precision: 1.0
recall: 0.182
using median
Calculating medians (means) per cluster: 100%|██████████| 16/16 [00:00<00:00, 320.85it/s]
Saving supplementary table as...
../../outputs_layer1/marker_eval_markers_onTarget_supp.csv
Saving supplementary table as...
../../outputs_layer1/marker_eval_markers_onTarget.csv
Saving final results table as...
../../outputs_layer1/marker_eval_results.csv
Saving final results table as...
../../outputs_layer1/marker_eval_results.pkl
--- 0.7569146156311035 seconds ---
[34]:
evaluation_results
[34]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | markers | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.945098 | 0.987705 | 0.806020 | 569 | 3 | 58 | 241 | 2 | [SLC17A7, CDH13] | 0.548527 |
| 1 | 4.1 | cluster | g1_g48_GLI3_Astro_Gja1 | 48 | 0.892857 | 1.000000 | 0.625000 | 823 | 0 | 18 | 30 | 2 | [GLI3, GJA1] | 0.854088 |
| 2 | 4.1 | cluster | g2_g27_APBB1IP_Micro_Ctss | 27 | 0.384615 | 1.000000 | 0.111111 | 844 | 0 | 24 | 3 | 2 | [APBB1IP, CTSS] | 0.955321 |
| 3 | 4.1 | cluster | g3_g18_GPNMB_OPC_Pdgfra | 18 | 0.928571 | 1.000000 | 0.722222 | 853 | 0 | 5 | 13 | 2 | [GPNMB, PDGFRA] | 0.680299 |
| 4 | 4.1 | cluster | g4_g9_MOG_Oligo_Opalin | 9 | 0.909091 | 1.000000 | 0.666667 | 862 | 0 | 3 | 6 | 2 | [MOG, OPALIN] | 1.000000 |
| 5 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.468750 | 0.750000 | 0.187500 | 854 | 1 | 13 | 3 | 3 | [TSPAN12, VIP, MYBPC1] | 0.209097 |
| 6 | 4.1 | cluster | i11_i6_EGF_Vip_Mybpc1 | 6 | 0.000000 | 0.000000 | 0.000000 | 865 | 0 | 6 | 0 | 3 | [EGF, VIP, MYBPC1] | 0.112842 |
| 7 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.879888 | 0.940299 | 0.700000 | 777 | 4 | 27 | 63 | 2 | [COL5A2, NDNF] | 0.608344 |
| 8 | 4.1 | cluster | i2_i77_LHX6_Sst_Cbln4 | 77 | 0.117647 | 1.000000 | 0.025974 | 794 | 0 | 75 | 2 | 3 | [LHX6, SST, CBLN4] | 0.420224 |
| 9 | 4.1 | cluster | i3_i56_BAGE2_Ndnf_Cxcl14 | 56 | 0.564516 | 0.823529 | 0.250000 | 812 | 3 | 42 | 14 | 3 | [BAGE2, NDNF, CXCL14] | 0.103398 |
| 10 | 4.1 | cluster | i4_i54_MC4R_Ndnf_Cxcl14 | 54 | 0.719178 | 0.913043 | 0.388889 | 815 | 2 | 33 | 21 | 3 | [MC4R, NDNF, CXCL14] | 0.351766 |
| 11 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.000000 | 0.000000 | 0.000000 | 803 | 21 | 47 | 0 | 2 | [TRPC3, NDNF] | 0.292197 |
| 12 | 4.1 | cluster | i6_i44_GPR149_Vip_Mybpc1 | 44 | 0.187500 | 0.333333 | 0.068182 | 821 | 6 | 41 | 3 | 3 | [GPR149, VIP, MYBPC1] | 0.235686 |
| 13 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.354839 | 0.354839 | 0.354839 | 820 | 20 | 20 | 11 | 3 | [CLMP, NDNF, CXCL14] | 0.180560 |
| 14 | 4.1 | cluster | i8_i27_SNCG_Vip_Mybpc1 | 27 | 0.000000 | 0.000000 | 0.000000 | 844 | 0 | 27 | 0 | 3 | [SNCG, VIP, MYBPC1] | 0.153438 |
| 15 | 4.1 | cluster | i9_i22_TAC3_Vip_Mybpc1 | 22 | 0.526316 | 1.000000 | 0.181818 | 849 | 0 | 18 | 4 | 3 | [TAC3, VIP, MYBPC1] | 0.288938 |
Plotting classification metrics from marker evaluation
[35]:
ns.pl.boxplot(evaluation_results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_boxplot_f_score.html
[36]:
ns.pl.boxplot(evaluation_results, "precision", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_boxplot_precision.html
[37]:
ns.pl.boxplot(evaluation_results, "recall", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_boxplot_recall.html
[38]:
ns.pl.boxplot(evaluation_results, "onTarget", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_boxplot_onTarget.html
[39]:
ns.pl.scatter_w_clusterSize(evaluation_results, "f_score", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_scatter_f_score.html
[40]:
ns.pl.scatter_w_clusterSize(evaluation_results, "precision", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_scatter_precision.html
[41]:
ns.pl.scatter_w_clusterSize(evaluation_results, "recall", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_scatter_recall.html
[42]:
ns.pl.scatter_w_clusterSize(evaluation_results, "onTarget", save = True, output_folder = output_folder, outputfilename_prefix = outputfilename_prefix)
Saving...
../../outputs_layer1/marker_eval_scatter_onTarget.html
Plotting scanpy dot plot, violin plot, matrix plot for input marker list
Note: Assign pre-defined dendrogram order here or use adata.uns["dendrogram_" + cluster_header]["categories_ordered"].
[43]:
to_plot = evaluation_results.copy()
[44]:
dendrogram = [] # custom dendrogram order
dendrogram = list(adata.uns["dendrogram_" + cluster_header]["categories_ordered"])
to_plot["clusterName"] = to_plot["clusterName"].astype("category")
to_plot["clusterName"] = to_plot["clusterName"].cat.set_categories(dendrogram)
to_plot = to_plot.sort_values("clusterName").reset_index(drop = True)
to_plot = to_plot.rename(columns = {"NSForest_markers": "markers"})
to_plot.head()
[44]:
| software_version | cluster_header | clusterName | clusterSize | f_score | precision | recall | TN | FP | FN | TP | marker_count | markers | onTarget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.1 | cluster | e1_e299_SLC17A7_L5b_Cdh13 | 299 | 0.945098 | 0.987705 | 0.806020 | 569 | 3 | 58 | 241 | 2 | [SLC17A7, CDH13] | 0.548527 |
| 1 | 4.1 | cluster | i7_i31_CLMP_Ndnf_Cxcl14 | 31 | 0.354839 | 0.354839 | 0.354839 | 820 | 20 | 20 | 11 | 3 | [CLMP, NDNF, CXCL14] | 0.180560 |
| 2 | 4.1 | cluster | i1_i90_COL5A2_Ndnf_Car4 | 90 | 0.879888 | 0.940299 | 0.700000 | 777 | 4 | 27 | 63 | 2 | [COL5A2, NDNF] | 0.608344 |
| 3 | 4.1 | cluster | i5_i47_TRPC3_Ndnf_Car4 | 47 | 0.000000 | 0.000000 | 0.000000 | 803 | 21 | 47 | 0 | 2 | [TRPC3, NDNF] | 0.292197 |
| 4 | 4.1 | cluster | i10_i16_TSPAN12_Vip_Mybpc1 | 16 | 0.468750 | 0.750000 | 0.187500 | 854 | 1 | 13 | 3 | 3 | [TSPAN12, VIP, MYBPC1] | 0.209097 |
[45]:
markers_dict = dict(zip(to_plot["clusterName"], to_plot["markers"]))
markers_dict
[45]:
{'e1_e299_SLC17A7_L5b_Cdh13': ['SLC17A7', 'CDH13'],
'i7_i31_CLMP_Ndnf_Cxcl14': ['CLMP', 'NDNF', 'CXCL14'],
'i1_i90_COL5A2_Ndnf_Car4': ['COL5A2', 'NDNF'],
'i5_i47_TRPC3_Ndnf_Car4': ['TRPC3', 'NDNF'],
'i10_i16_TSPAN12_Vip_Mybpc1': ['TSPAN12', 'VIP', 'MYBPC1'],
'i4_i54_MC4R_Ndnf_Cxcl14': ['MC4R', 'NDNF', 'CXCL14'],
'i9_i22_TAC3_Vip_Mybpc1': ['TAC3', 'VIP', 'MYBPC1'],
'i6_i44_GPR149_Vip_Mybpc1': ['GPR149', 'VIP', 'MYBPC1'],
'i8_i27_SNCG_Vip_Mybpc1': ['SNCG', 'VIP', 'MYBPC1'],
'g1_g48_GLI3_Astro_Gja1': ['GLI3', 'GJA1'],
'g3_g18_GPNMB_OPC_Pdgfra': ['GPNMB', 'PDGFRA'],
'g2_g27_APBB1IP_Micro_Ctss': ['APBB1IP', 'CTSS'],
'g4_g9_MOG_Oligo_Opalin': ['MOG', 'OPALIN'],
'i2_i77_LHX6_Sst_Cbln4': ['LHX6', 'SST', 'CBLN4'],
'i11_i6_EGF_Vip_Mybpc1': ['EGF', 'VIP', 'MYBPC1'],
'i3_i56_BAGE2_Ndnf_Cxcl14': ['BAGE2', 'NDNF', 'CXCL14']}
[46]:
ns.pl.dotplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\dotplot_marker_eval.png
C:\Users\bpeng\AppData\Local\anaconda3\Lib\site-packages\scanpy\plotting\_dotplot.py:747: UserWarning:
No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
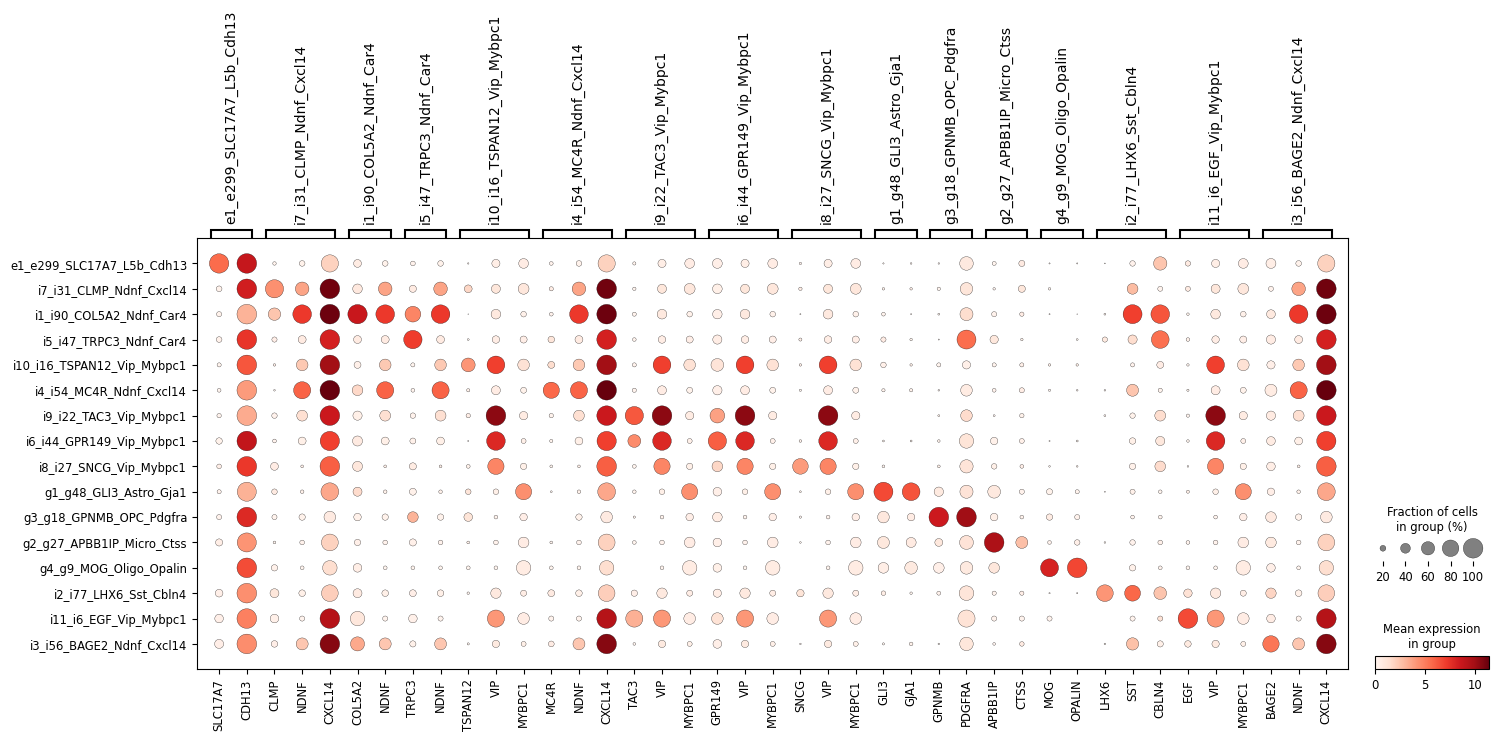
[47]:
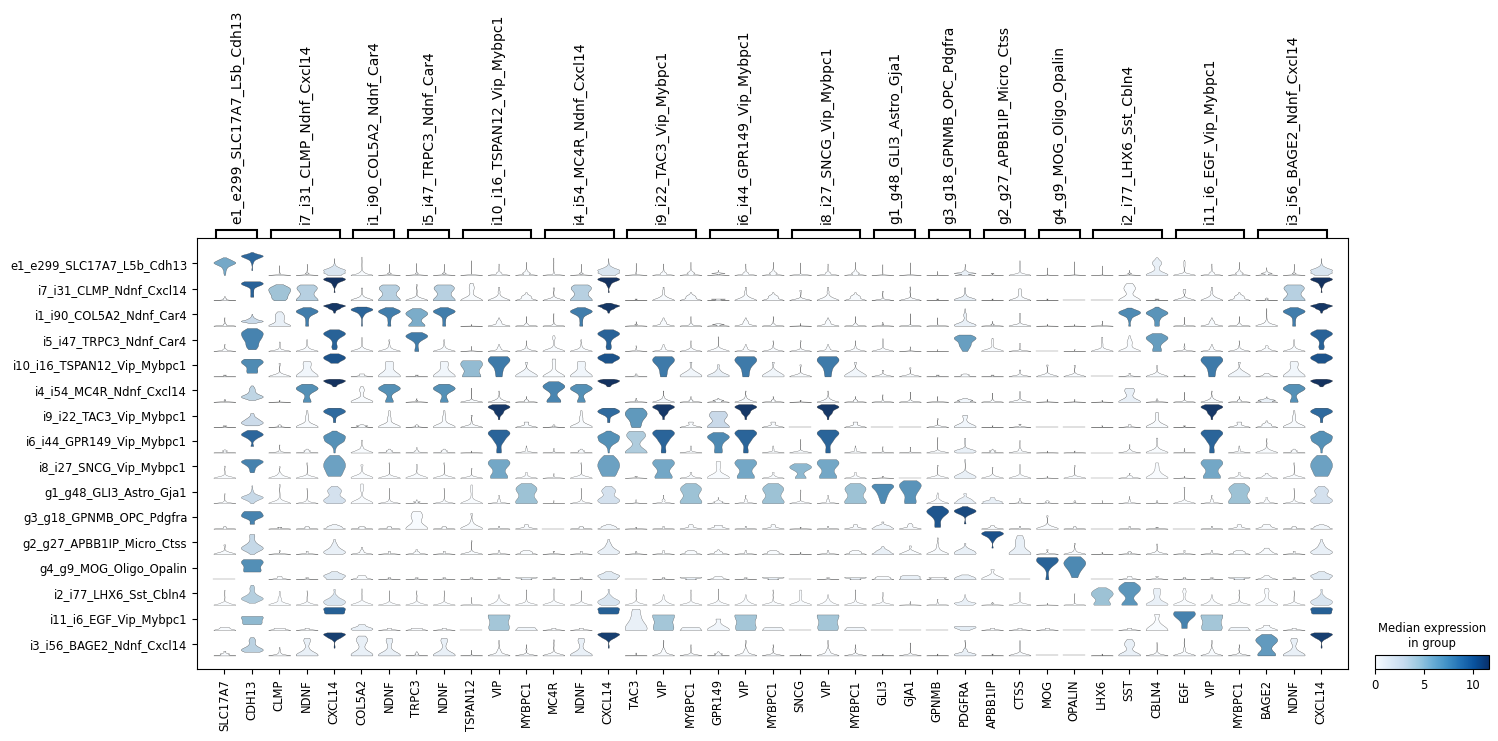
ns.pl.stackedviolin(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\stacked_violin_marker_eval.png
[48]:
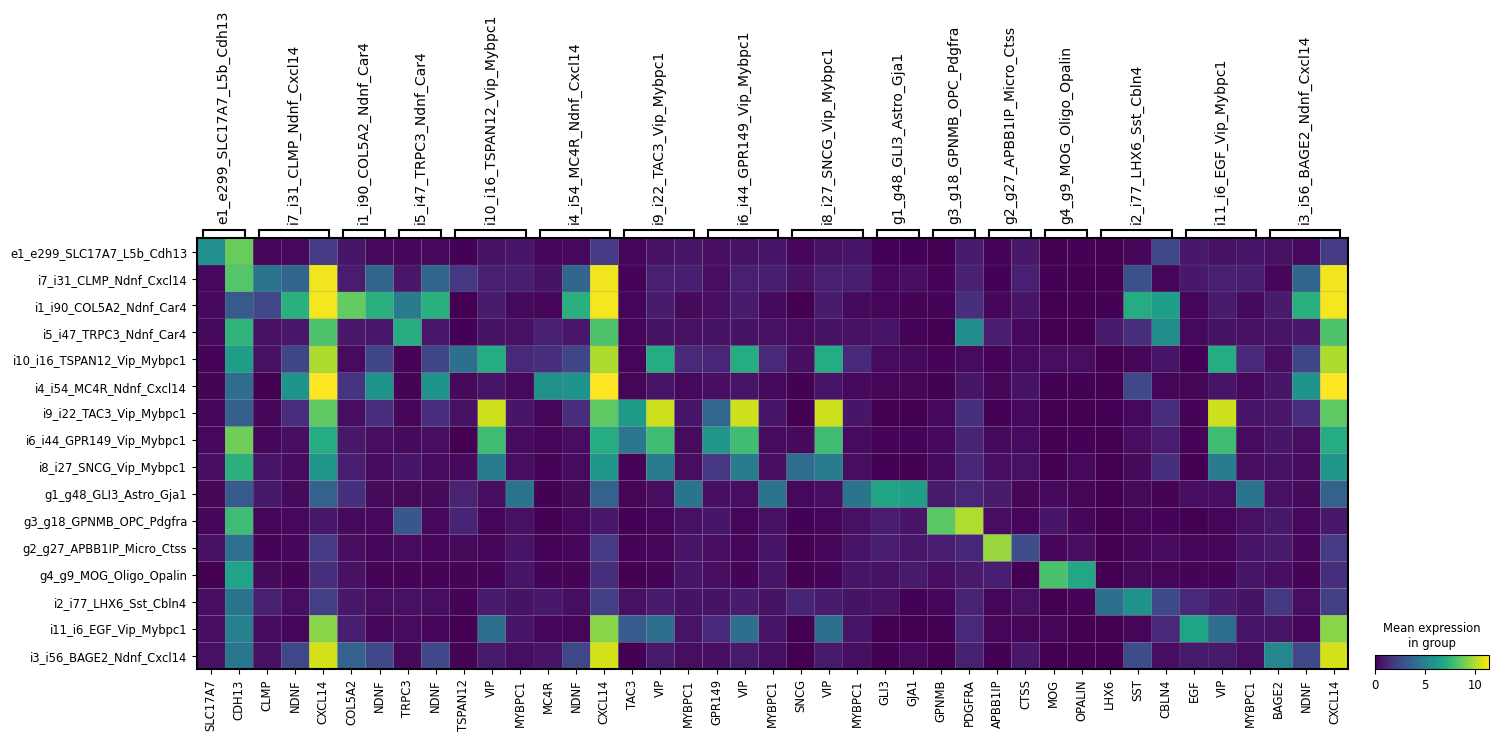
ns.pl.matrixplot(adata, markers_dict, cluster_header, dendrogram = dendrogram, save = True, output_folder = output_folder, outputfilename_suffix = outputfilename_prefix)
WARNING: saving figure to file ..\..\outputs_layer1\matrixplot_marker_eval.png
[49]:
adata
[49]:
AnnData object with n_obs × n_vars = 871 × 16497
obs: 'cluster'
uns: 'dendrogram_cluster'
obsm: 'X_pca'
[50]:
adata_subset
[50]:
AnnData object with n_obs × n_vars = 871 × 11688
obs: 'cluster'
uns: 'dendrogram_cluster'
obsm: 'X_pca'
varm: 'medians_cluster', 'binary_scores_cluster'